Explore Workflows
View already parsed workflows here or click here to add your own
| Graph | Name | Retrieved From | View |
|---|---|---|---|
|
|
QuantSeq 3' mRNA-Seq single-read
### Pipeline for Lexogen's QuantSeq 3' mRNA-Seq Library Prep Kit FWD for Illumina [Lexogen original documentation](https://www.lexogen.com/quantseq-3mrna-sequencing/) * Cost-saving and streamlined globin mRNA depletion during QuantSeq library preparation * Genome-wide analysis of gene expression * Cost-efficient alternative to microarrays and standard RNA-Seq * Down to 100 pg total RNA input * Applicable for low quality and FFPE samples * Single-read sequencing of up to 9,216 samples/lane * Dual indexing and Unique Molecular Identifiers (UMIs) are available ### QuantSeq 3’ mRNA-Seq Library Prep Kit FWD for Illumina The QuantSeq FWD Kit is a library preparation protocol designed to generate Illumina compatible libraries of sequences close to the 3’ end of polyadenylated RNA. QuantSeq FWD contains the Illumina Read 1 linker sequence in the second strand synthesis primer, hence NGS reads are generated towards the poly(A) tail, directly reflecting the mRNA sequence (see workflow). This version is the recommended standard for gene expression analysis. Lexogen furthermore provides a high-throughput version with optional dual indexing (i5 and i7 indices) allowing up to 9,216 samples to be multiplexed in one lane. #### Analysis of Low Input and Low Quality Samples The required input amount of total RNA is as low as 100 pg. QuantSeq is suitable to reproducibly generate libraries from low quality RNA, including FFPE samples. See Fig.1 and 2 for a comparison of two different RNA qualities (FFPE and fresh frozen cryo-block) of the same sample. 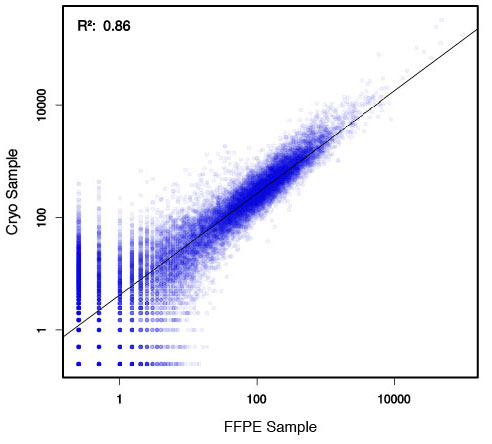 Figure 1 | Correlation of gene counts of FFPE and cryo samples. 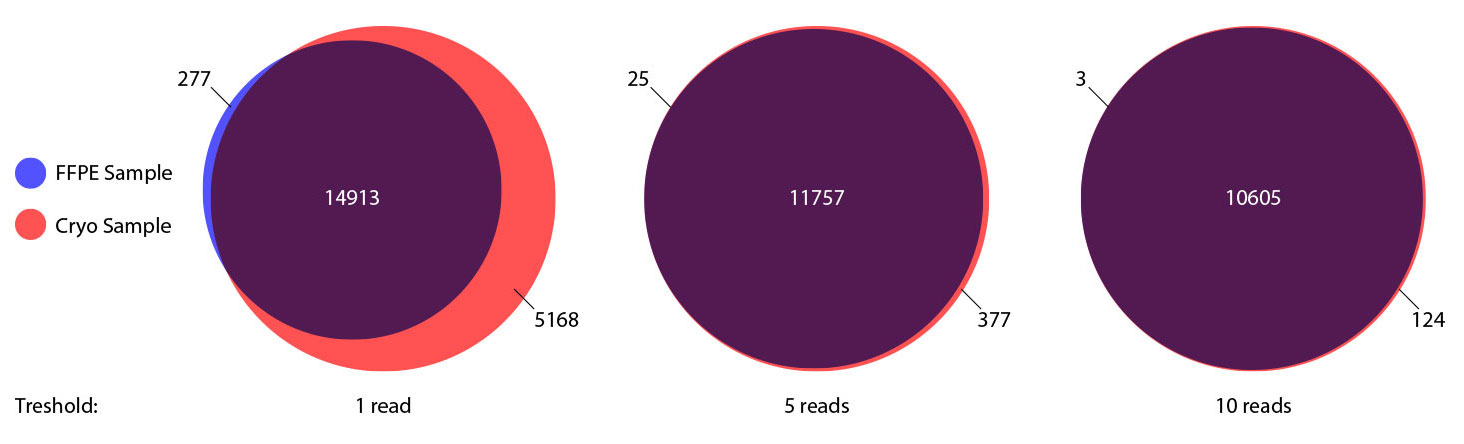 Figure 2 | Venn diagrams of genes detected by QuantSeq at a uniform read depth of 2.5 M reads in FFPE and cryo samples with 1, 5, and 10 reads/gene thresholds. #### Mapping of Transcript End Sites By using longer reads QuantSeq FWD allows to exactly pinpoint the 3’ end of poly(A) RNA (see Fig. 3) and therefore obtain accurate information about the 3’ UTR. 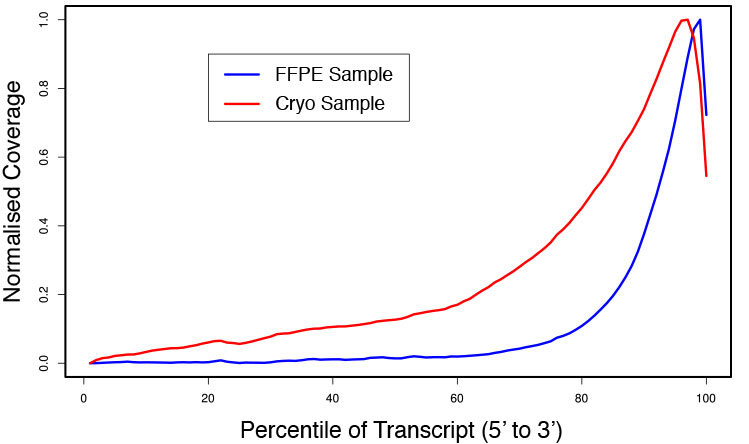 Figure 3 | QuantSeq read coverage versus normalized transcript length of NGS libraries derived from FFPE-RNA (blue) and cryo-preserved RNA (red). ### Current workflow should be used only with the single-end RNA-Seq data. It performs the following steps: 1. Separates UMIes and trims adapters from input FASTQ file 2. Uses ```STAR``` to align reads from input FASTQ file according to the predefined reference indices; generates unsorted BAM file and alignment statistics file 3. Uses ```fastx_quality_stats``` to analyze input FASTQ file and generates quality statistics file 4. Uses ```samtools sort``` and generates coordinate sorted BAM(+BAI) file pair from the unsorted BAM file obtained on the step 2 (after running STAR) 5. Uses ```umi_tools dedup``` and generates final filtered sorted BAM(+BAI) file pair 6. Generates BigWig file on the base of sorted BAM file 7. Maps input FASTQ file to predefined rRNA reference indices using ```bowtie``` to define the level of rRNA contamination; exports resulted statistics to file 8. Calculates isoform expression level for the sorted BAM file and GTF/TAB annotation file using GEEP reads-counting utility; exports results to file |
Path: workflows/trim-quantseq-mrnaseq-se.cwl Branch/Commit ID: 36fd18f11e939d3908b1eca8d2939402f7a99b0f |
|
|
|
tt_blastn_wnode
|
Path: task_types/tt_blastn_wnode.cwl Branch/Commit ID: 1b8d71c75156a1a62bf0477d59db26010e2dcc29 |
|
|
|
pindel parallel workflow
|
Path: definitions/subworkflows/pindel.cwl Branch/Commit ID: 44ada20f3eeb59005d5bd999d2435102e9bae991 |
|
|
|
varscan somatic workflow
|
Path: definitions/subworkflows/varscan.cwl Branch/Commit ID: 31602b94b34ff55876147c7299e1bec47e8d1a31 |
|
|
|
ChIP-Seq pipeline paired-end
The original [BioWardrobe's](https://biowardrobe.com) [PubMed ID:26248465](https://www.ncbi.nlm.nih.gov/pubmed/26248465) **ChIP-Seq** basic analysis workflow for a **paired-end** experiment. A [FASTQ](http://maq.sourceforge.net/fastq.shtml) input file has to be provided. The pipeline produces a sorted BAM file alongside with index BAI file, quality statistics of the input FASTQ file, coverage by estimated fragments as a BigWig file, peaks calling data in a form of narrowPeak or broadPeak files, islands with the assigned nearest genes and region type, data for average tag density plot. Workflow starts with step *fastx\_quality\_stats* from FASTX-Toolkit to calculate quality statistics for input FASTQ file. At the same time `bowtie` is used to align reads from input FASTQ file to reference genome *bowtie\_aligner*. The output of this step is an unsorted SAM file which is being sorted and indexed by `samtools sort` and `samtools index` *samtools\_sort\_index*. Depending on workflow’s input parameters indexed and sorted BAM file can be processed by `samtools rmdup` *samtools\_rmdup* to get rid of duplicated reads. If removing duplicates is not required the original BAM and BAI files are returned. Otherwise step *samtools\_sort\_index\_after\_rmdup* repeat `samtools sort` and `samtools index` with BAM and BAI files without duplicates. Next `macs2 callpeak` performs peak calling *macs2\_callpeak* and the next step reports *macs2\_island\_count* the number of islands and estimated fragment size. If the latter is less that 80bp (hardcoded in the workflow) `macs2 callpeak` is rerun again with forced fixed fragment size value (*macs2\_callpeak\_forced*). It is also possible to force MACS2 to use pre set fragment size in the first place. Next step (*macs2\_stat*) is used to define which of the islands and estimated fragment size should be used in workflow output: either from *macs2\_island\_count* step or from *macs2\_island\_count\_forced* step. If input trigger of this step is set to True it means that *macs2\_callpeak\_forced* step was run and it returned different from *macs2\_callpeak* step results, so *macs2\_stat* step should return [fragments\_new, fragments\_old, islands\_new], if trigger is False the step returns [fragments\_old, fragments\_old, islands\_old], where sufix \"old\" defines results obtained from *macs2\_island\_count* step and sufix \"new\" - from *macs2\_island\_count\_forced* step. The following two steps (*bamtools\_stats* and *bam\_to\_bigwig*) are used to calculate coverage from BAM file and save it in BigWig format. For that purpose bamtools stats returns the number of mapped reads which is then used as scaling factor by bedtools genomecov when it performs coverage calculation and saves it as a BEDgraph file whichis then sorted and converted to BigWig format by bedGraphToBigWig tool from UCSC utilities. Step *get\_stat* is used to return a text file with statistics in a form of [TOTAL, ALIGNED, SUPRESSED, USED] reads count. Step *island\_intersect* assigns nearest genes and regions to the islands obtained from *macs2\_callpeak\_forced*. Step *average\_tag\_density* is used to calculate data for average tag density plot from the BAM file. |
Path: workflows/chipseq-pe.cwl Branch/Commit ID: 5561f7ee11dd74848680351411a19aa87b13d27b |
|
|
|
protein similarities
run diamond on mutlple DBs and merge-sort results |
Path: CWL/Workflows/protein-diamond.workflow.cwl Branch/Commit ID: 6a8727124baf77416ca797982fd4e0689c2a593a |
|
|
|
hmmsearch_wnode and gpx_qdump combined workflow to apply scatter/gather
|
Path: task_types/tt_hmmsearch_wnode_plus_qdump.cwl Branch/Commit ID: ac387721a55fd91df3dcdf16e199354618b136d1 |
|
|
|
count-lines3-wf.cwl
|
Path: cwltool/schemas/v1.0/v1.0/count-lines3-wf.cwl Branch/Commit ID: 65aedc5e7e1f3ccace7f9022f8a54b3f0d5c9a8c |
|
|
|
exome alignment and germline variant detection, with optitype for HLA typing
|
Path: definitions/pipelines/germline_exome_hla_typing.cwl Branch/Commit ID: 788bdc99c1d5b6ee7c431c3c011eb30d385c1370 |
|
|
|
wf-loadContents2.cwl
|
Path: tests/wf-loadContents2.cwl Branch/Commit ID: 31ec48a8d81ef7c1b2c5e9c0a19e7623efe4a1e2 |

