Workflow: GATK-complete-WES-Workflow-h3abionet.cwl
# H3ABioNet GATK Germline Workflow # Overview A [GATK best-practices](https://software.broadinstitute.org/gatk/best-practices/bp_3step.php?case=GermShortWGS) germline workflow designed to work with GATK 3.5 (Van der Auwera et al., 2013). For more information see our [GitHub](https://github.com/h3abionet/h3agatk) site. # Workflow Summary 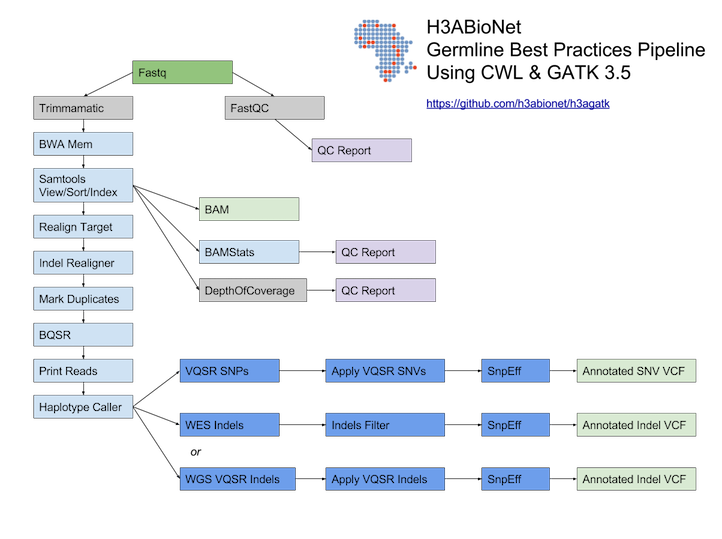 # Workflow Tool Details ## FastQC FastQC is used as an initial QC step where the input files are checked for usual metrics such as: - Read length - Reads distribution - GC content - ... ## Trimmomatic Trimmomatic is the entry point of the pipeline, it is used to cleanup the reads in the input fastq files from any sequencing adaptors. ## BWA [BWA](http://bio-bwa.sourceforge.net) is used to align the reads from the the input fastq files -paired-ends- (Li, 2013). We use specifically `bwa mem` as recommended by the [GATK best-practices](https://software.broadinstitute.org/gatk/best-practices/bp_3step.php?case=GermShortWGS). BWA produces a SAM file containing the aligned reads against the human reference genome (hg19, GATK bundle build 2.8). As GATK tools downstream requires properly formatted Read Group information. We add by default 'toy' Read Group information while processing the alignment to the output SAM file. we specifically use the flag `-R '@RG\tID:foo\tSM:bar\tLB:library1'`. ## SAMtools [SAMtools](http://www.htslib.org) (Li et al., 2009) are used few times in the pipeline: 1. Convert BWA's output from a SAM format to a BAM format 2. Sort the reads in the generated BAM file in step 1 (above) 3. Indexing the BAM file for the following tools to use ## Picard [Picard tools](https://broadinstitute.github.io/picard/) are used to mark duplicated reads in the aligned and sorted BAM file, making thus the files lighter and less prone to errors in the downstream steps of the pipeline. ## GATK [Genome Analysis Tool Kit](https://software.broadinstitute.org/gatk) refered to as GATK (DePristo et al., 2011) is used to process the data throught multiple steps as described by the [GATK best-practices](https://software.broadinstitute.org/gatk/best-practices/bp_3step.php?case=GermShortWGS) (i.e. figure bellow). 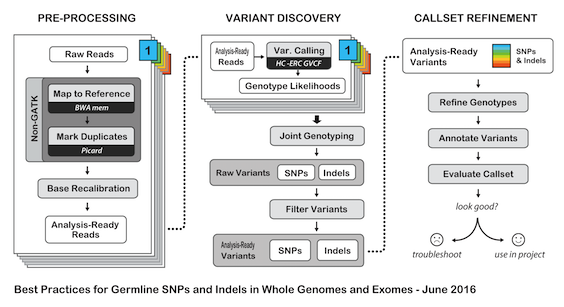 The GATK steps are the following: 1. Indel Realignment: 1. [Realign Target Creator](https://software.broadinstitute.org/gatk/documentation/tooldocs/org_broadinstitute_gatk_tools_walkers_indels_RealignerTargetCreator.php) 2. [Indel Realigner](https://software.broadinstitute.org/gatk/documentation/tooldocs/org_broadinstitute_gatk_tools_walkers_indels_IndelRealigner.php) 2. Mark Duplicates (a picard step) 3. Base Quality Score Recalibration (BQSR): 1. [Base Recalibrator](https://software.broadinstitute.org/gatk/documentation/tooldocs/org_broadinstitute_gatk_tools_walkers_bqsr_BaseRecalibrator.php) 2. [Print Reads](https://software.broadinstitute.org/gatk/documentation/tooldocs/org_broadinstitute_gatk_tools_walkers_readutils_PrintReads.php) 4. [Haplotype Caller](https://software.broadinstitute.org/gatk/documentation/tooldocs/) 5. Variant Quality Score Recalibration (VQSR): 1. [Variant Recalibrator](https://software.broadinstitute.org/gatk/documentation/tooldocs/org_broadinstitute_gatk_tools_walkers_variantrecalibration_VariantRecalibrator.php) 2. [Apply Recalibration](https://software.broadinstitute.org/gatk/documentation/tooldocs/org_broadinstitute_gatk_tools_walkers_variantrecalibration_ApplyRecalibration.php) ## SnpEff SNPEff is used in this pipeline to annotate the variant calls (Cingolani et al., 2012). The annotation is extensive and uses multi-database approach to provide the user with as much information about the called variants as possible. ## BAMStat [BAMStats](http://bamstats.sourceforge.net), is a simple software tool built on the Picard Java API (2), which can calculate and graphically display various metrics derived from SAM/BAM files of value in QC assessments.
- Selected
- |
- Default Values
- Nested Workflows
- Tools
- Inputs/Outputs
Inputs
| ID | Type | Title | Doc |
|---|---|---|---|
| dbsnp | File |
vcf file containing SNP variations used for Haplotype caller |
|
| reads | File[] (Optional) |
files containing the paired end reads in fastq format required for bwa-mem |
|
| tmpdir | String (Optional) |
temporary dir for picard |
|
| gatk_jar | File |
Jar executable of the GATK tool |
|
| covariate | String[] (Optional) |
required for base recalibrator |
|
| reference | File |
reference human genome file |
|
| bwa_threads | Integer |
number of threads |
|
| snpf_genome | String | ||
| gatk_threads | Integer |
number of threads |
|
| resource_1kg | File | ||
| resource_omni | File | ||
| snpf_data_dir | Directory | ||
| bwa_read_group | String |
read group |
|
| resource_dbsnp | File | ||
| resource_mills | File | ||
| bwa_output_name | String |
name of bwa-mem output file |
|
| resource_hapmap | File | ||
| snpf_nodownload | Boolean | ||
| known_variant_db | File[] (Optional) |
array of known variant files for realign target creator |
|
| samtools_threads | Integer |
number of threads |
|
| filter_expression | String | ||
| samtools-index-bai | Boolean |
boolean set to output bam file from samtools view |
|
| samtools-view-isbam | Boolean |
boolean set to output bam file from samtools view |
|
| output_samtools-sort | String |
output file name for bam file generated by samtools sort |
|
| output_samtools-view | String |
output file name for bam file generated by samtools view |
|
| samtools-view-sambam | String (Optional) |
temporary dir for picard |
|
| snpeff_java_mem_opts | String[] (Optional) |
memory options passed to the java command run for snpEff |
|
| uncompressed_reference | File |
reference human genome file |
|
| output_RefDictionaryFile | String |
output file name for picard create dictionary command from picard toolkit |
|
| outputFileName_PrintReads | String |
name of PrintReads command output file |
|
| readSorted_MarkDuplicates | String |
set to be true showing that reads are sorted already |
|
| createIndex_MarkDuplicates | String |
set to be true to create .bai file from Picard Mark Duplicates |
|
| metricsFile_MarkDuplicates | String |
metric file generated by MarkDupicates command listing duplicates |
|
| depth_omitIntervalStatistics | Boolean (Optional) |
Do not calculate per-interval statistics |
|
| outputFileName_IndelRealigner | String |
name of indelRealigner output file |
|
| outputFileName_MarkDuplicates | String |
output file name generated as a result of Markduplicates command from picard toolkit |
|
| outputFileName_HaplotypeCaller | String |
name of Haplotype caller command output file |
|
| depth_omitDepthOutputAtEachBase | Boolean (Optional) |
Do not output depth of coverage at each base |
|
| outputFileName_BaseRecalibrator | String |
name of BaseRecalibrator output file |
|
| removeDuplicates_MarkDuplicates | String |
set to be true |
|
| depth_outputfile_DepthOfCoverage | String (Optional) |
name of the output report basename |
|
| outputFileName_RealignTargetCreator | String |
name of realignTargetCreator output file |
Steps
| ID | Runs | Label | Doc |
|---|---|---|---|
| SnpVQSR |
GATK-Sub-Workflow-h3abionet-snp.cwl
(Workflow)
|
||
| IndelFilter | |||
| HaplotypeCaller |
Outputs
| ID | Type | Label | Doc |
|---|---|---|---|
| output_bamstat | File | ||
| output_printReads | File | ||
| output_HaplotypeCaller | File | ||
| output_SnpVQSR_recal_File | File | ||
| output_SnpVQSR_annotated_snps | File | ||
| output_IndelFilter_annotated_indels | File |
https://w3id.org/cwl/view/git/3f7a70fac81d7b70362c1587a6142e373a97d0ad/workflows/GATK/GATK-complete-WES-Workflow-h3abionet.cwl

